

September 23, 2025
Unstrukturierte Dokumente wie PDFs, Scans oder Office-Dateien enthalten wertvolles Wissen – für Large Language Models (LLMs) sind sie aber schwer direkt verwertbar. Wer bessere Antworten von LLMs möchte, sollte diese Daten zuerst in ein strukturiertes Format überführen. Besonders Markdown hat sich bewährt, da es die Dokumentstruktur erhält (Überschriften, Listen, Tabellen, Bilder, Formeln, Codeblöcke). Das verbessert das Verständnis der Modelle, reduziert Halluzinationen und steigert die Qualität von Retrieval-Augmented-Generation (RAG) Pipelines deutlich.
Im Markt haben sich drei Lösungen etabliert, die unstrukturierte Dokumente automatisch in Markdown konvertieren: Mistral OCR (Cloud-Service), IBM Docling (Open Source, lokal) und MinerU (Open Source, Forschungskontext). Im Folgenden der Vergleich.
Mistral OCR ist ein KI-basierter API-Dienst zur Dokumentenverarbeitung.
Für Unternehmen, die auf Qualität und Geschwindigkeit setzen bietet Mistral die im Moment leistungsstärkste Lösung und ist dabei auch AI-konform nach europäischem Recht.
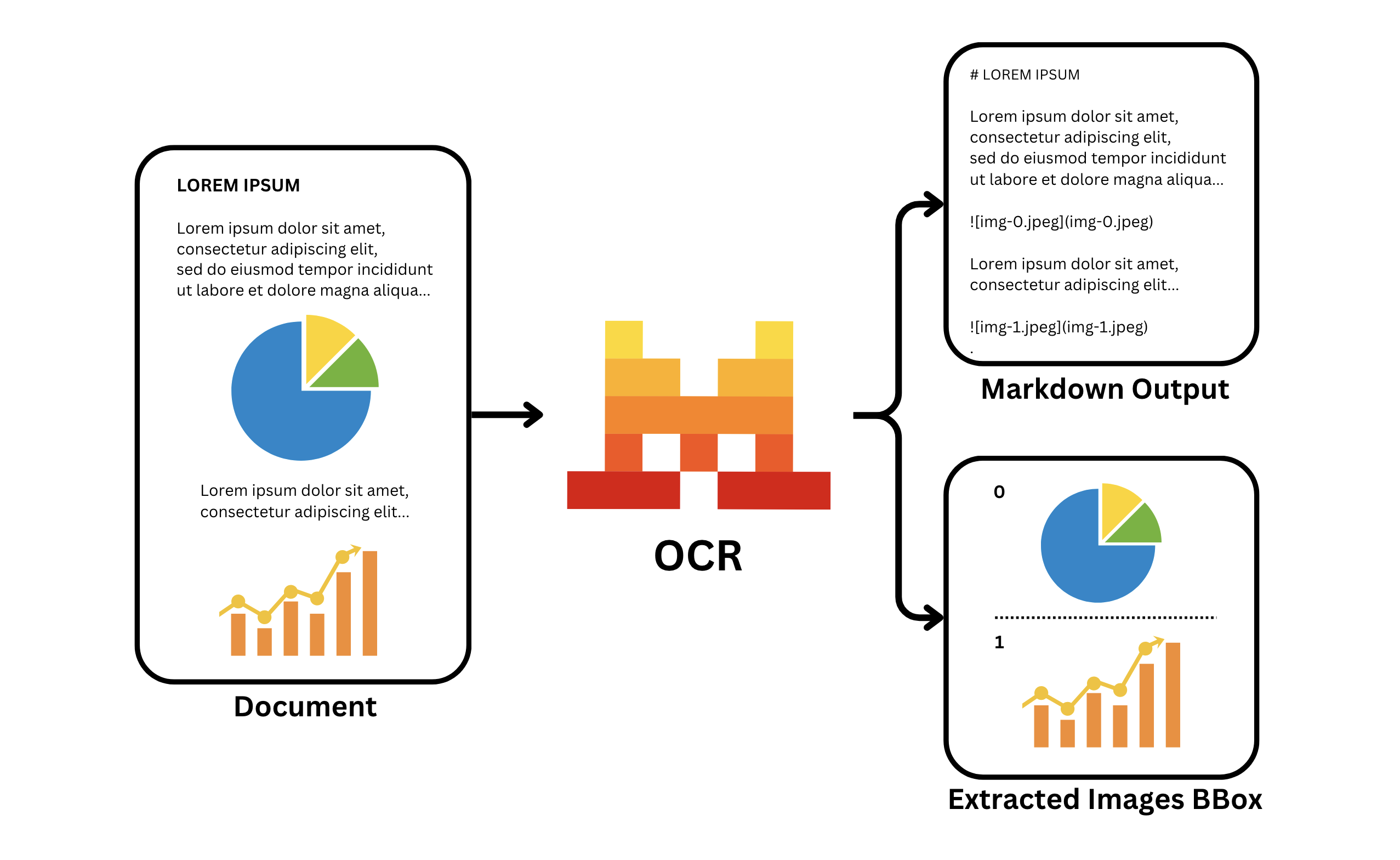
Docling ist ein von IBM Research entwickeltes Open-Source-Toolkit.
Docling ist besonders attraktiv für Unternehmen, die Datensouveränität und Open-Source-Prinzipien hoch priorisieren.
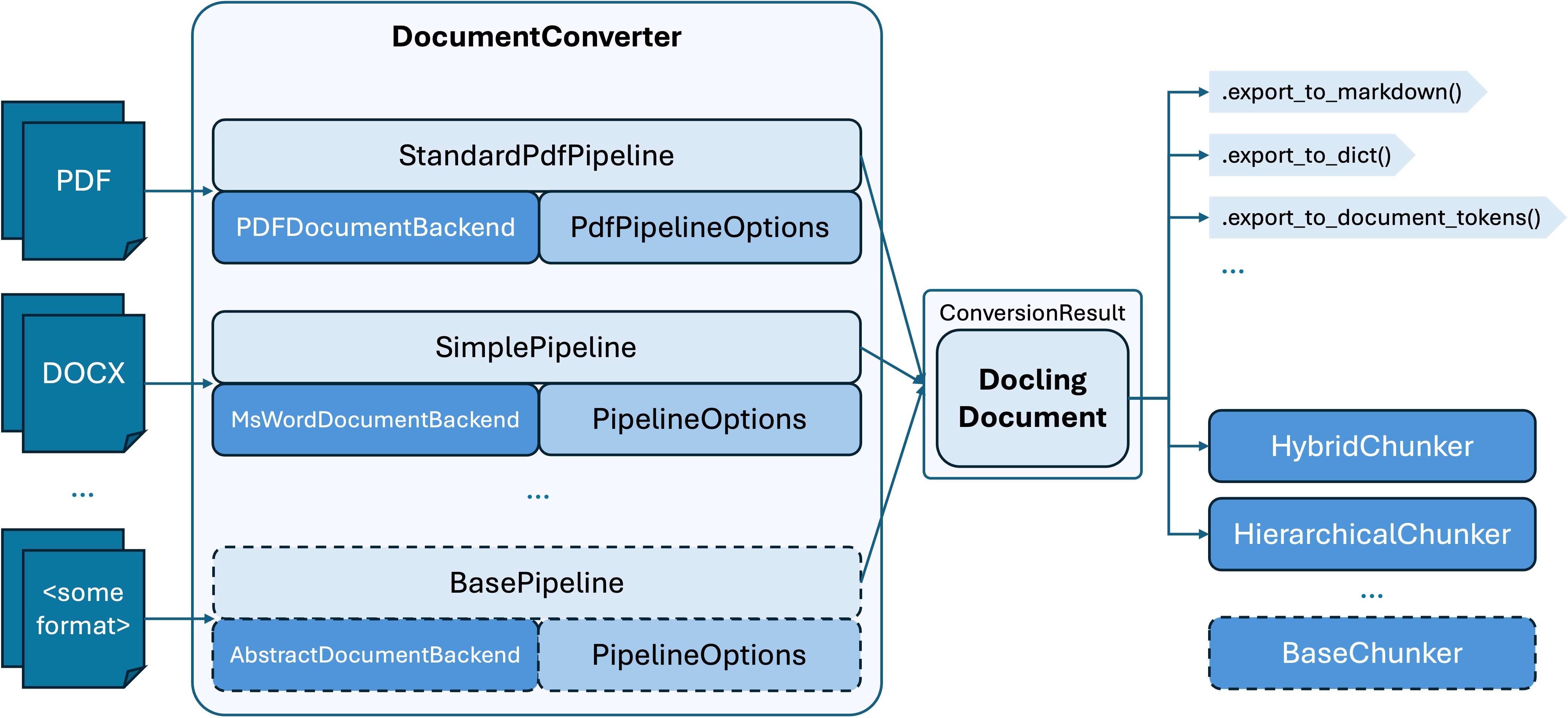
MinerU wurde im akademischen Umfeld entwickelt und punktet mit einigen Spezialfunktionen.
MinerU ist spannend für forschungsnahe oder technisch anspruchsvolle Szenarien, muss sich aber noch im Unternehmenseinsatz bewähren.
Alle drei Tools verbessern die Qualität von LLMs erheblich, indem sie unstrukturierte Dokumente in strukturiertes Markdown umwandeln. Open-Source-Ansätze wie Docling und MinerU sind starke Optionen für Organisationen, die maximale Kontrolle über ihre Daten benötigen und eigene Infrastruktur betreiben wollen.
Doch wer schnell, skalierbar und mit höchster Erkennungsqualität arbeiten möchte, findet derzeit in Mistral OCR die beste Lösung – gerade für europäische Kunden. Mistral kombiniert technologische Spitzenleistung mit einfacher Integration und ist damit ideal, um unstrukturierte Daten effizient für LLMs nutzbar zu machen.
https://github.com/docling-project/docling
https://mistral.ai/news/mistral-ocr

