

September 23, 2025
Unstructured documents such as PDFs, scans, or Office files contain valuable knowledge – but Large Language Models (LLMs) struggle to use them directly. To improve answer quality, it’s best to first convert such data into a structured format. Markdown has proven particularly effective, as it preserves document structures (headings, lists, tables, images, formulas, code blocks). This improves LLM understanding, reduces hallucinations, and significantly boosts the performance of Retrieval-Augmented Generation (RAG) pipelines.
Several tools now automate this conversion from unstructured documents into Markdown. The three most relevant solutions are Mistral OCR (cloud service), IBM Docling (open source, local), and MinerU (open source, research context). Below is a comparison of their strengths and weaknesses.
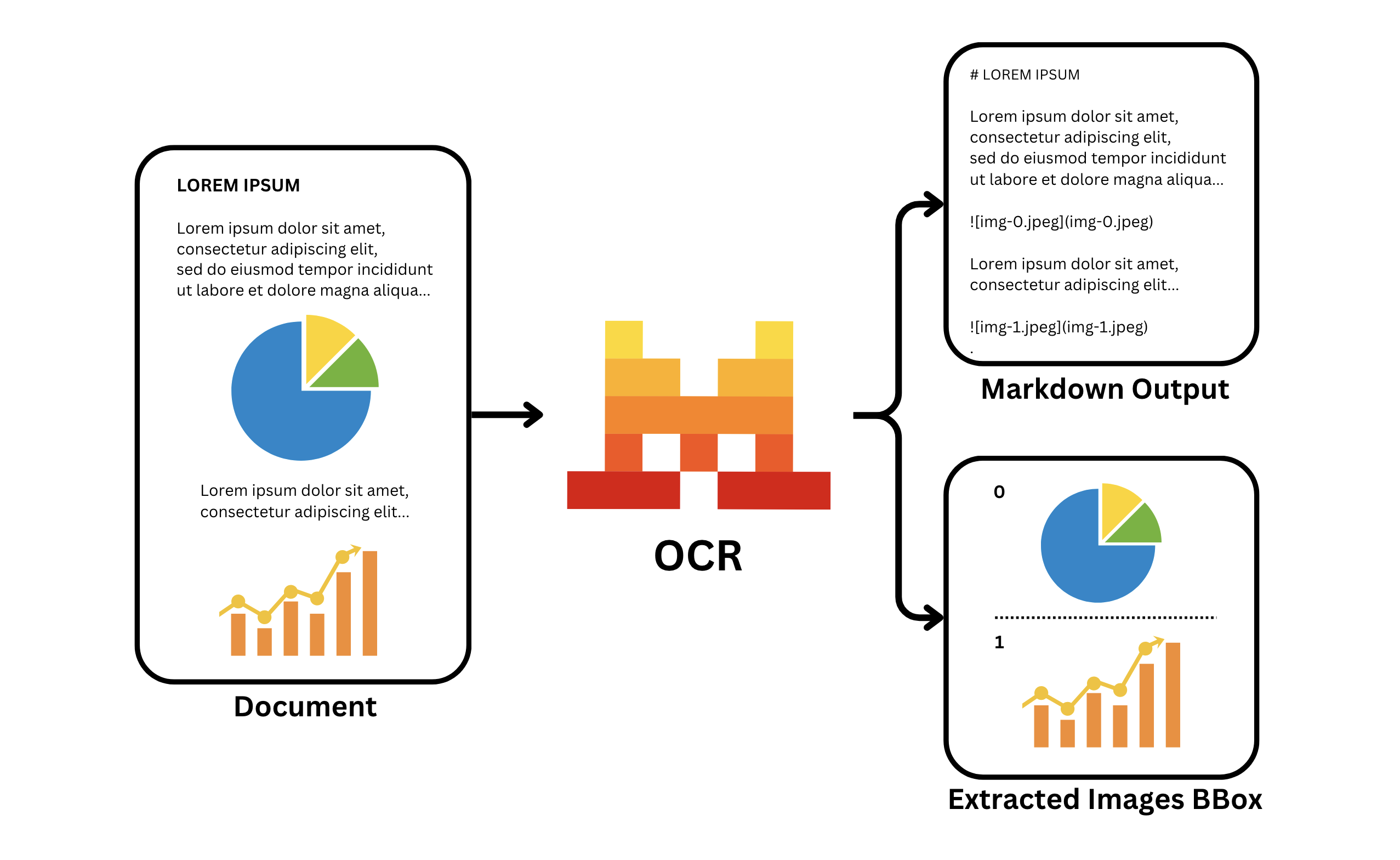
Mistral OCR is an AI-powered document processing service delivered via API.
For companies focused on speed and top-quality results, Mistral is the most powerful solution currently available.
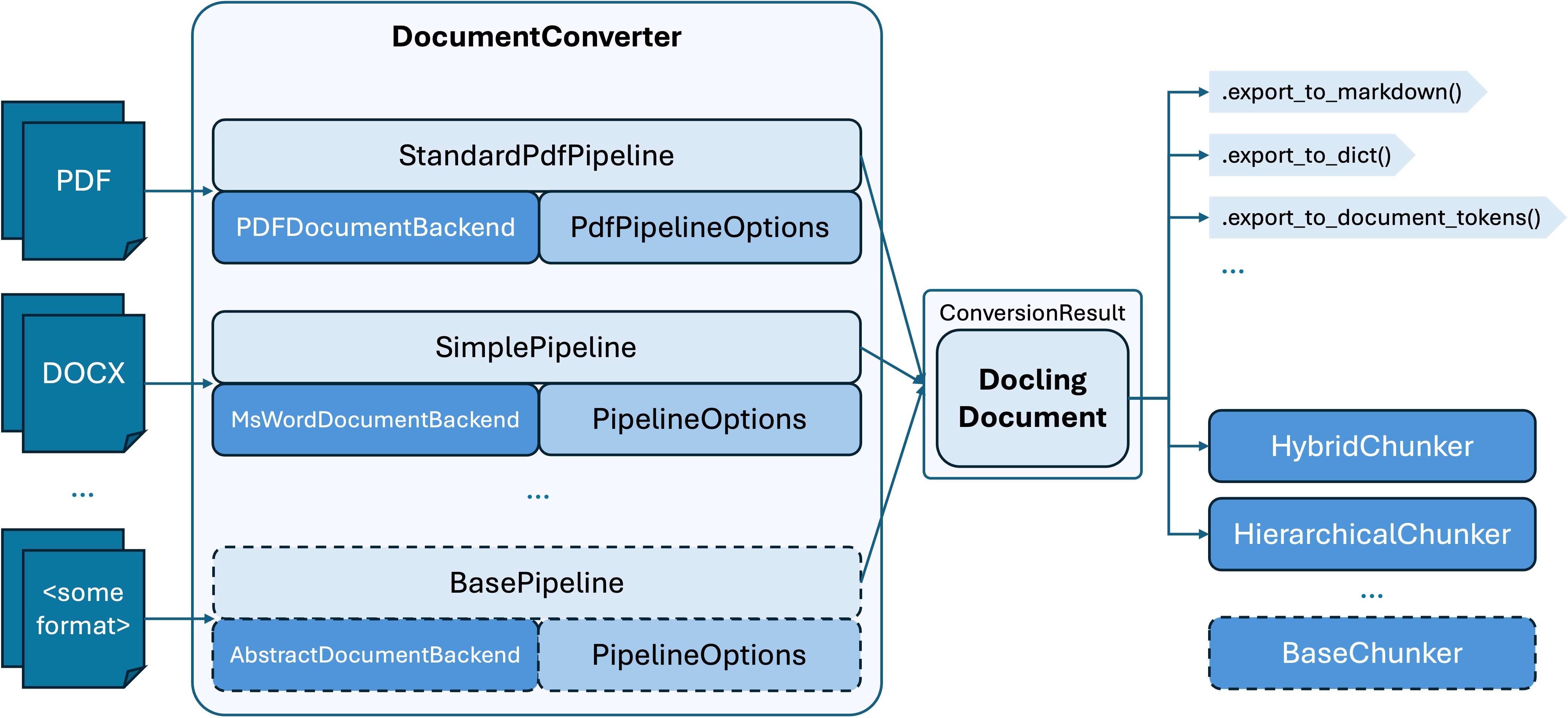
Docling is an open-source toolkit developed by IBM Research.
Docling is well-suited for organizations prioritizing data sovereignty and open-source flexibility.
MinerU was developed in an academic context and focuses on scientific and technical use cases.
MinerU is promising for research-heavy or technical domains, but still needs to mature for enterprise-scale use.
All three tools improve LLM performance by transforming unstructured documents into structured Markdown. Open-source approaches like Docling and MinerU are compelling for organizations that demand full control and are willing to run their own infrastructure.
However, for those who need speed, scalability, and the highest recognition accuracy out of the box, Mistral OCR currently stands out as the best solution – particularly for European customers. It combines state-of-the-art performance with ease of integration, making unstructured data truly usable for LLM-driven applications.
https://github.com/docling-project/docling
https://mistral.ai/news/mistral-ocr

